

AI Super resolution usually leverages deep neural networks optimised for CV. Convolutional neural networks (CNNs) have been a mainstay of CV for several decades, and are normally used for things like image classification, an early example of which is how Yann LeCun used CNNs to learn how to classify handwritten digits, allowing cheques to be cashed autonomously.
Background: CNNs for classification
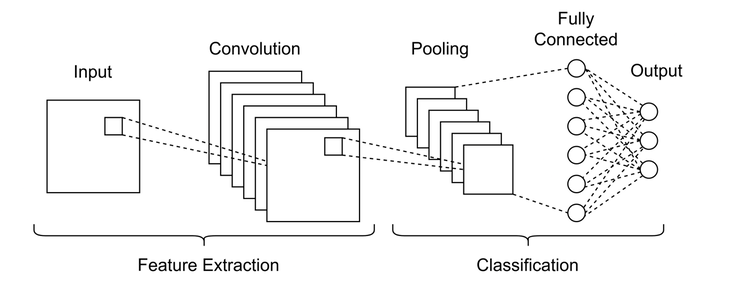
Background: CNNs for other systems
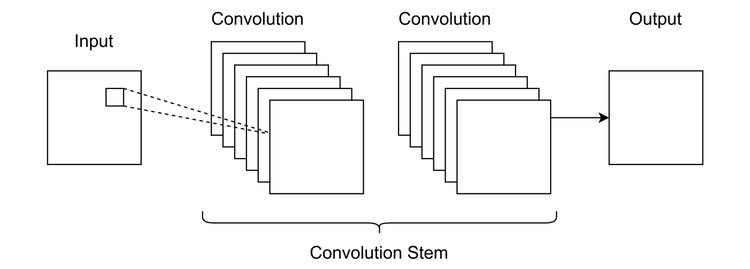
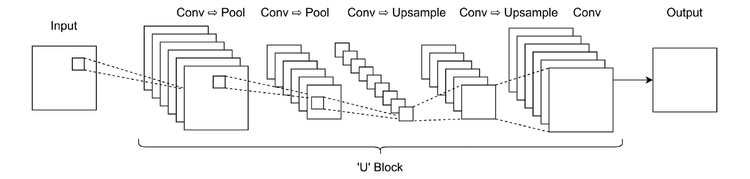
Dilation upsampling (aka sup-pixel convolution),
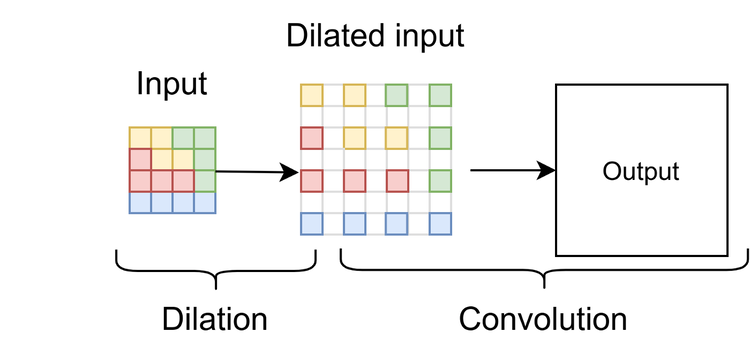
Multi-channel reshape upsampling (aka resize convolution)
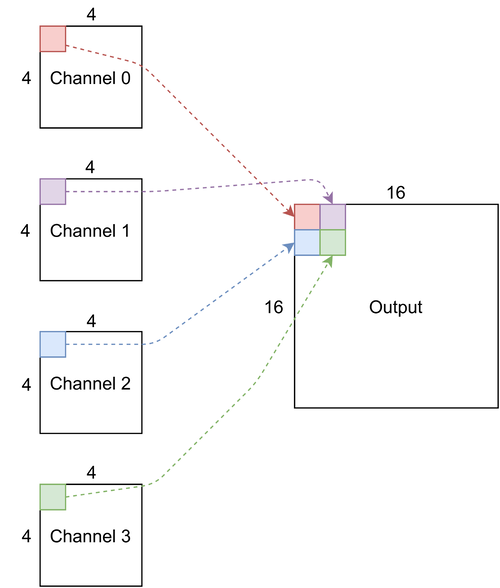
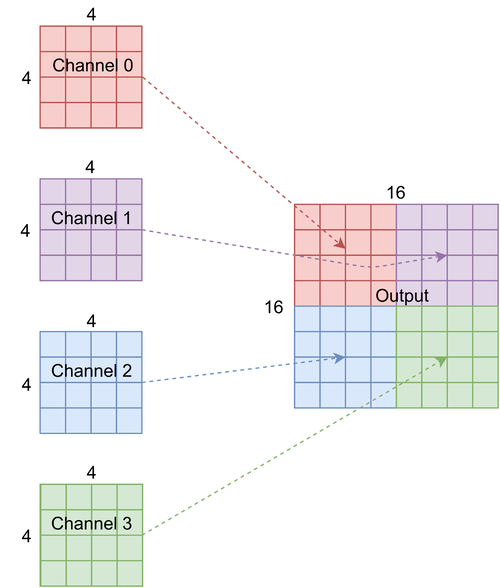
Data & hardware
Data for super resolution experiments is abundant. Images need not be classified or labelled in any way, the only prerequisite is that training images should be at least as big as the resolution we wish to upsample to.
We used a python web scraper that downloads images returned by Google image search when fed keywords like ‘lion’:
from selenium import webdriver
from PIL import Image
import os
import time
import io
import requests
import hashlib
def fetch_image_urls(query: str, max_links_to_fetch: int, wd: webdriver, sleep_between_interactions: int = 1):
def scroll_to_end(wd):
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(sleep_between_interactions)
search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img"
wd.get(search_url.format(q=query))
image_urls = set()
image_count = 0
results_start = 0
load_mode_iterations = 0
while image_count < max_links_to_fetch:
scroll_to_end(wd)
thumbnail_results = wd.find_elements_by_css_selector("img.Q4LuWd")
number_results = len(thumbnail_results)
print(
f"Found: {number_results} search results. Extracting links from {results_start}:{number_results}")
for img in thumbnail_results[results_start:number_results]:
try:
img.click()
time.sleep(sleep_between_interactions)
except Exception:
continue
actual_images = wd.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'http' in actual_image.get_attribute('src'):
image_urls.add(actual_image.get_attribute('src'))
image_count = len(image_urls)
if (len(image_urls) >= max_links_to_fetch):
print(f"Found: {len(image_urls)} image links, done!")
break
else:
print("Found:", len(image_urls),
"image links, looking for more ...")
time.sleep(1)
load_mode_iterations += 1
if load_mode_iterations > 15:
print(
f"Giving up. Found: {len(image_urls)} image links, done!")
return image_urls
load_more_button = wd.find_element_by_css_selector(".mye4qd")
if load_more_button:
wd.execute_script("document.querySelector('.mye4qd').click();")
results_start = len(thumbnail_results)
return image_urls
def persist_image(folder_path: str, url: str):
try:
image_content = requests.get(url, timeout=10).content
except Exception as e:
print(f"ERROR - Could not download {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
_w, _h = image.size
min_dim = min(_w, _h)
if (min_dim < IMAGE_SIZE):
raise RuntimeError('Image too small: ' + str(_w) + ' ' + str(_h))
else:
half_min_dim = int(min_dim / 2)
centre_h = int(_h / 2)
centre_w = int(_w / 2)
start_h = centre_h - half_min_dim
start_w = centre_w - half_min_dim
end_h = start_h + min_dim
end_w = start_w + min_dim
image = image.crop((start_w, start_h, end_w, end_h))
image = image.resize((IMAGE_SIZE, IMAGE_SIZE))
file_path = os.path.join(folder_path, hashlib.sha1(
image_content).hexdigest()[:10] + '.jpg')
with open(file_path, 'wb') as f:
image.save(f, "JPEG")
print(f"SUCCESS - Saved image from {url}")
except Exception as e:
print(f"ERROR - Could not save {url} - {e}")
def search_and_download(search_term: str, driver_path: str, target_path='images', number_images=5):
target_folder = os.path.join(target_path, "_".join(search_term.split()))
if not os.path.exists(target_folder):
os.makedirs(target_folder)
with webdriver.Chrome(executable_path=driver_path) as wd:
res = fetch_image_urls(search_term, number_images,
wd=wd, sleep_between_interactions=0.1)
for elem in res:
persist_image(target_folder, elem)
DRIVER_PATH = 'scraping/chromedriver.exe'
IMAGE_SIZE = 256
if __name__ == '__main__':
search_and_download('citrus fruit', DRIVER_PATH, number_images=1000)
search_and_download('leaves', DRIVER_PATH, number_images=1000)
search_and_download('rainforest', DRIVER_PATH, number_images=1000)
search_and_download('cuttlefish', DRIVER_PATH, number_images=1000)
search_and_download('lion', DRIVER_PATH, number_images=1000)
Images large enough were downloaded, cropped square and resized to our target upscaled resolution: 256². This process was repeated until we had a unique dataset of around 14,000 images. The images were split into 70% training and 30% validation subsets. PyTorch dataloaders were used to load the datasets.
Training setup
During training and validation, the 3-channel, 256²-sized images in the dataset were used as the ground truth values. Inputs to the network were created by downsizing the ground truth images to 3-channel 32² using the nearest neighbour algorithm. Electronic training took place on an Nvidia Quadro P6000.
We wanted our convolutional layers to be performed by Optalysys’ optical chip, so we used our PyTorch layer to interface with the Optalysys silicon photonic free-space Fourier optical chip in the lab. Prototype networks were run electronically, once suitable hyperparameters were chosen, the optical network could be called by passing ‘optical=True’ to our model when initialising.
Our upsampling technique
We wrote code that defines an upsample block of varying channel depth and convolutional layer count. The block could then be parameterised into an entire network with a single upsample at the end, or multiple blocks could be stacked together to create larger end-to-end network upsample factors. The block can also be combined with conv → pool type blocks for a U-net super resolution architecture.
Avoiding checkerboarding

Upsample block PyTorch code
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorchlayer.opt_conv_layer import OptConvLayer
# makes a matrix sparse by padding within: e.g. [1,2,3] -> [0,1,0,2,0,3,0]
def pad_within(x, stride=2):
w = x.new_zeros(stride, stride)
w[0, 0] = 1
return F.conv_transpose2d(x, w.expand(x.size(1), 1, stride, stride), stride=stride, groups=x.size(1))
# takes a 4d array (BxCxHxW) where (channels // 4) == 0
# returns a channel upsampled array with H and W x2 and C /4
def channel_upsample2d(x):
start_shape = x.shape
target_shape = (start_shape[0], int(start_shape[1] / 4), start_shape[2]*2, start_shape[3]*2)
assert(x.ndim == 4)
assert(not (x.shape[1] % 4))
x = pad_within(x, 2)
w = x.view(-1, 4, x.shape[2], x.shape[3])
w[:, 1] = w[:, 1].roll(shifts=(1,0), dims=(1,2))
w[:, 2] = w[:, 2].roll(shifts=(0,1), dims=(1,2))
w[:, 3] = w[:, 3].roll(shifts=(1,1), dims=(1,2))
w = w.sum(axis=1)
return w.view(target_shape)
# convolutional block that takes a 4d input (BxCxHxW), does multi channel-convolutions, internally increases the channel
# dimension to 4x the input channel dimension, then multichannel upsamples to output something with H & W 2x increased
class UpsampleBlock(nn.Module):
def __init__(self, depth, length, kernel_size, padding, optical=False, padding_mode='zeros') -> None:
super(UpsampleBlock, self).__init__()
self.conv_layer_count = length
self.depth = depth
if optical:
self.conv_layers = nn.ModuleList([
OptConvLayer(depth if ch == 0 else depth * 4, depth * 4, kernel_size=kernel_size, padding=padding,
perfect_gradient=True)
for ch in range(self.conv_layer_count)])
else:
self.conv_layers = nn.ModuleList([
nn.Conv2d(depth if ch == 0 else depth * 4, depth * 4, kernel_size=kernel_size, padding=padding,
padding_mode=padding_mode)
for ch in range(self.conv_layer_count)])
self.fix_initialisation()
def forward(self, x):
layer_input = x
for i, layer in enumerate(self.conv_layers):
x = F.elu(layer(x))
# add residual connections
ind = torch.tensor([i for i in range(0, self.depth*4, 4)])
for i in range(4):
x[:, ind+i] += layer_input
return channel_upsample2d(x)
# fix checkerboard pattern
def fix_initialisation(self):
with torch.no_grad():
for q in range(self.conv_layers[self.conv_layer_count-1].weight.shape[0] // 4):
for ich in range(self.conv_layers[self.conv_layer_count-1].weight.shape[1]):
w0 = self.conv_layers[self.conv_layer_count-1].weight[q * 4, ich]
b0 = self.conv_layers[self.conv_layer_count-1].bias[q * 4]
for i in range(4):
self.conv_layers[self.conv_layer_count-1].weight[q * 4 + i, ich] = nn.Parameter(w0)
self.conv_layers[self.conv_layer_count - 1].bias[q * 4 + i] = nn.Parameter(b0)
For our experiment we used 3 upsample blocks of depth 4 and length (number of internal multichannel convolution layers) 4, 2 and 1 from input to output respectively. We defined an end-to-end model consisting of a single convolution layer with 3×3-sized filters, several unsample blocks with 3×3-sized filters, then a 1×1 convolution layer at the end for channel reduction.
Here’s the code for the model:
import torch.nn as nn
import torch.nn.functional as F
from upsample import UpsampleBlock
from pytorchlayer.opt_conv_layer import OptConvLayer
class SuperResolutionModel(nn.Module):
in_channels = 3
out_channels = 3
upsample_block_depth = [4, 4, 4]
upsample_block_length = [4, 2, 1]
upsample_block_count = 3
upsample_kernel_size = 3
default_padding = 1
def __init__(self, optical=False):
super(SuperResolutionModel, self).__init__()
if optical:
self.c1 = OptConvLayer(self.in_channels, self.upsample_block_depth[0], kernel_size=self.upsample_kernel_size,
padding=self.default_padding, perfect_gradient=True)
self.cf = OptConvLayer(self.upsample_block_depth[-1], self.out_channels, kernel_size=1,
padding=0, perfect_gradient=True)
else:
self.c1 = nn.Conv2d(self.in_channels, self.upsample_block_depth[0], kernel_size=self.upsample_kernel_size,
padding=self.default_padding, padding_mode='replicate')
self.cf = nn.Conv2d(self.upsample_block_depth[-1], self.out_channels, kernel_size=1,
padding=0, padding_mode='replicate')
self.c_stem = nn.ModuleList([
UpsampleBlock(
self.upsample_block_depth[i], self.upsample_block_length[i], self.upsample_kernel_size,
self.default_padding, optical=optical, padding_mode='replicate')
for i in range(self.upsample_block_count)])
def forward(self, x):
x = F.elu(self.c1(x))
for block in self.c_stem:
x = block(x)
x = self.cf(x)
return x
For training, we found that a batch size of 4 worked well for our experiments. We trained the model with a stepped learning rate starting at 0.01 with a gamma of 0.8 for around 15 epochs.

def mge_loss(prediction, target):
x_filter = torch.tensor([[-1, -2, -1],
[0, 0, 0],
[1, 2, 1.0]]).unsqueeze(0).repeat(3, 1, 1).unsqueeze(0).cuda() / 8
y_filter = torch.tensor([[-1, 0, 1],
[-2, 0, 2],
[1, 0, 1.0]]).unsqueeze(0).repeat(3, 1, 1).unsqueeze(0).cuda() / 8
replication_pad = nn.ReplicationPad2d(1)
gx_prediction = F.conv2d(replication_pad(prediction), x_filter)
gy_prediction = F.conv2d(replication_pad(prediction), y_filter)
gx_target = F.conv2d(replication_pad(target), x_filter)
gy_target = F.conv2d(replication_pad(target), y_filter)
mge_x = F.mse_loss(gx_prediction, gx_target) / 2.0
mge_y = F.mse_loss(gy_prediction, gy_target) / 2.0
return (mge_x + mge_y) * mge_loss_scale

def normalised_squared_euclidean_distance(m_1, m_2):
return torch.mean(torch.square(m_1 - m_2))
def vgg_feature_loss(prediction, target, loss_model):
p_features = loss_model.forward_features(prediction).relu2_2
t_features = loss_model.forward_features(target).relu2_2
return normalised_squared_euclidean_distance(p_features, t_features)
The above code requires a loss_model object, which can be instantiated from a class such as this (the example also has style loss functionality as mentioned by Johnson et al., though style loss is not recommended for super resolution):
def normalised_squared_euclidean_distance(m_1, m_2):
return torch.mean(torch.square(m_1 - m_2))
def vgg_feature_loss(prediction, target, loss_model):
p_features = loss_model.forward_features(prediction).relu2_2
t_features = loss_model.forward_features(target).relu2_2
return normalised_squared_euclidean_distance(p_features, t_features)


Background: The Optalysys approach

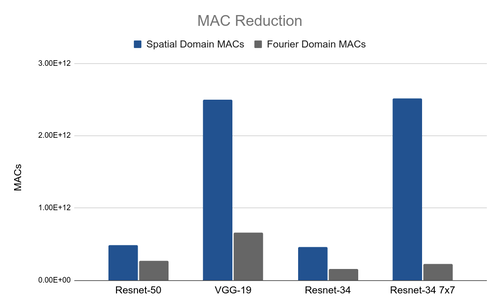
We also describe this idea in more detail in this article.
Super resolution experiments on an optical computer


The awesome thing about end-to-end CNN architectures (unlike transformers and CNNs with dense layers) is that they will work for any inputs of any size. The convolutional layers work in the same way, regardless of the height and width of the input. This means that we can use the same network, originally trained on 32² 8x upscaling, on larger inputs. We can, for instance, take the 256² data in the dataset and upscale it to 2048².
As the data was originally gathered from scraping the web, there are artefacts in many of the images consistent with lossy JPEG like compression. Can the CNN be used to restore the image quality while also increasing the resolution? Below are some examples of the networks being used in this way; we were amazed by the results.
Thanks for reading!
by Ed@Optalysys — [email protected]
Left: Bicubic upsampling — 256² → 2048²
Original images have some lossy compression artefacts.
Right: Optical CNN — 256² → 2048²
















{kind=link}