
Fourier-optical computing technology of the kind developed by Optalysys has the capacity to deliver tremendous improvements in the computational speed and power consumption needed for artificial intelligence algorithms, but that’s not the only field to which the technology can be applied. The Fourier transform is incredibly versatile, and there are many seemingly unrelated problems which can benefit from a faster method of performing it.
One of these fields is a category of new methods for performing encryption, the process by which information is mathematically scrambled for security purposes. It’s expected that quantum computing will pose a major risk to some of the existing techniques that keep communications secret and secure, so we need new post-quantum encryption methods that don’t share the same mathematical vulnerabilities to quantum attacks.
While there have been a range of proposed alternatives for replacement methods, one of the most promising is known as lattice-based cryptography. In this approach, the mathematical security of the various cryptographic tools is provided by a range of “hard” problems on lattices, a class of mathematical objects with structures that repeat infinitely. We’ve described the basic security concepts of lattice-based cryptography in a previous article.
One of the great things about lattice cryptography is its flexibility; not only can it be used to replace the parts of cryptography that are vulnerable to quantum attack, but certain constructions of it can be used to perform entirely newforms of cryptography, enabling us to do things that we couldn’t do before.
Crucially, one of these new uses is of immense value, both commercially and from the perspective of user privacy. It is a technique that allows for complete security at all stages of remote data processing, even when that data is being worked on.
This new model of cryptography is known as Fully Homomorphic Encryption, or FHE.
However, the computational complexity of FHE has meant that until recently it simply hasn’t been practical to use at scale.
That is now changing; a combination of ever more powerful computers and significant advances in technical implementation are placing the benefits of FHE within reach, and the race is on to be the first to bring these spectacular advantages into the wider world.
At Optalysys, our optical Fourier-transform hardware has the ability to shatter one of the key computational bottlenecks which is currently slowing FHE down. Other companies taking aim at the problem include Zama, the first company dedicated to the development of FHE, as well as the computing giants IBM and Microsoft.
In this article, we describe the basic idea of what FHE is and how it functions, and then show how we can apply our optical computing system in performing some of the key stages in this new model of cryptography
Securing digital information has never been easy. The methods we use today work when applied correctly, but information breaches are still so common that news of a large cyber-attack or data theft is hardly surprising.
And while we provide a lot of information to various service providers without too many concerns, there are some things that we really want to keep secret. Most of us trust online services and sales portals with our credit card details because the damage that can be done with those is comparatively limited, but very few of us would be inclined to trust those same services with sensitive information such as medical or bank records.
This isn’t paranoia; most of us have some understanding of the dangers, even if only informally. We know that computers, computer software and encryption schemes are complex systems and that it is very hard to make such things definitively “secure”. We also know that not everyone is trustworthy; even if you trust a company, it only takes one corrupt employee for protected information to find its way into the wrong hands. And the numbers aren’t promising; in the US, 80% of 300 surveyed companies working in the cloud sector indicated that they had suffered at least 1 data breach in the last 18 months.
Giving over sensitive information for processing needs something a step beyond what is currently on offer, where even the most secure approaches are ultimately backed only by good IT practice and trust. It requires not only the kind of mathematical guarantee that encryption provides, but expert knowledge to ensure that the technical implementation is robust.
FHE gives us a way of meeting these requirements. And by combining cutting edge methods developed by Zama, with the unprecedented power and utility of our Fourier-optical computing system, we can present a new way forward for a commercially viable implementation of FHE.
. . .
So what is FHE, and how does it help? A significant part of why information on the internet should always be considered insecure to some degree is because of the way that encryption works. When browsing the internet, you usually transmit information over a channel secured with transport layer security (TLS). If you send details to a website, they are (hopefully!) stored in an encrypted form so that even if they’re stolen, they cannot be read.
But right now, computers cannot work on data which has been encrypted. Performing calculations on data requires that the underlying structure, the mathematical relationship between each element, is preserved.
One of the most fundamental properties of relationship preservation is known as homomorphism. For the purposes of understanding FHE, this means that when you add or multiply things together, then everything changes in a consistent way. Current encryption methods don’t preserve this structure (either fully or at all), so any time a service needs to work on the information you send it, it must first decrypt the data, making it vulnerable in the process.
Data encrypted using fully homomorphic encryption doesn’t need to be decrypted in order to work on it. Through some very clever mathematical tricks, it allows us to perform any calculation on encrypted data that we would on unencrypted data, although at significant computational cost. It is this computational cost which has kept FHE from realising its full potential; despite the development of the first fully homomorphic encryption scheme in 2009 (partially homomorphic schemes have existed since the invention of RSA in 1977), it was simply too calculation-intensive to be practical.
That has changed; not only are more modern computers more powerful, but recent advances in the way that FHE schemes are designed have driven the computational requirements down significantly. It’s still slower compared to working with unencrypted data, but not so slow that it can’t be useful.
This is revolutionary. Now, even sensitive data can be sent to a third party cloud service and stored, worked on, or searched without ever revealing the actual content of that data, even to the hardware that is working on it! At all stages the data remains safely encrypted. Because FHE is based on post-quantum cryptographic constructions, it’s even secure against the next generation of computing threats.
So, where do we start? To make a fully homomorphic encryption scheme, we need a way of hiding information in a mathematically secure way that still allows us to perform two basic operations on it; addition and multiplication.
The idea is that we can take our unencrypted data (we call this the “plaintext”) and encrypt it using an FHE-friendly method, creating a “ciphertext”. As a consequence of the property of homomorphism, if we add or multiply the contents of two or more ciphertexts together, then when we decrypt the result the plaintext we retrieve should be the same as if we’d performed the operations on unencrypted information.
This might not sound particularly useful; after all, we said above that FHE allows us to perform any calculation that we like on encrypted data. This is still true though, because while addition and multiplication are simple operations, they are all that is needed to implement a system of Boolean logic, the mathematical system behind the workings of modern computers. In an integrated circuit (such as a CPU), combinations of transistors are used to create electronic gates that perform operations in Boolean logic such as AND, OR, NOT and so on.
By creating a system of Boolean logic using addition and multiplication (technically all we need is the ability to perform either a NAND or NOR operation, as all other gates can be constructed using combinations of these gates), we can build a circuit of homomorphic operations equivalent to those that would be applied to the unencrypted data if worked on by a CPU.
This is great, but it is also incredibly slow compared to working on unencrypted data; the processor now has to perform a huge number of calculations just to mimic the behaviour of a single gate-level operation, the kind of fundamental task which is performed billions of times a second on a modern CPU core.
However, until recently, there were even bigger performance issues preventing FHE from being practical.
Almost* all current FHE schemes are based on a post-quantum cryptographic tool called the learning with errors (LWE) problem, in which the difficulty of recovering information hidden using LWE hinges on the difficulty of recovering a secret piece of information given only approximate solutions to vector problems that use that secret information.
LWE is a very versatile problem in cryptography; the mathematical security of LWE can be shown to be related to the difficulty of solving certain hard problems on lattices (and thus quantum-secure), and it preserves the all-important homomorphically additive and multiplicative properties that allows us to perform FHE. However, as a fundamental part of the LWE method, we have to add some random noise to the values we calculate using the secret information to make it secure.
This isn’t normally a problem for LWE (or the related ring-learning with errors problem; more on that in a bit), but it’s a major headache for FHE. It means that when we add or multiply two ciphertexts encrypted using an LWE method, the noise in the secret data also increases. This isn’t much of a problem for addition, but when we multiply, the noise increases quadratically. If we perform too many operations in a row, the noise becomes so great that we cannot reliably decrypt the information; it is lost forever. If we can only perform a limited number of operations before the information is lost, we can only evaluate circuits of limited depth. This is called a somewhat homomorphic encryption scheme.
It wasn’t until 2009 that Craig Gentry gave the world the first working FHE system, using lattice techniques which were closely (but not exactly) related to the learning with errors problem. Key to this development was Gentry recognising that the decryption process for an FHE scheme could also be converted into a circuit that can be performed using homomorphic operations. In essence, this allows an FHE scheme to execute it’s own decryption circuit!
Here’s why that’s useful. Under a normal LWE encryption scheme, we can decrypt the ciphertext to retrieve the plaintext, and this plaintext doesn’t have any noise in it at all.
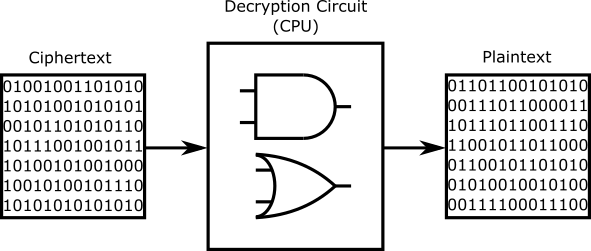
The normal way of decrypting a ciphertext, using a decryption circuit implemented on the CPU. Even if the data is encrypted using an LWE method, the plaintext contains no noise at all.
By passing the ciphertext and the decryption key through a decryption circuit executed using homomorphic operations, this produces a new ciphertext which has the same (or slightly higher) level of noise as a freshly-encrypted ciphertext. If it helps, think of the output of the homomorphic decryption circuit as a plaintext, albeit one which has been “decrypted” into a form which is still encrypted.
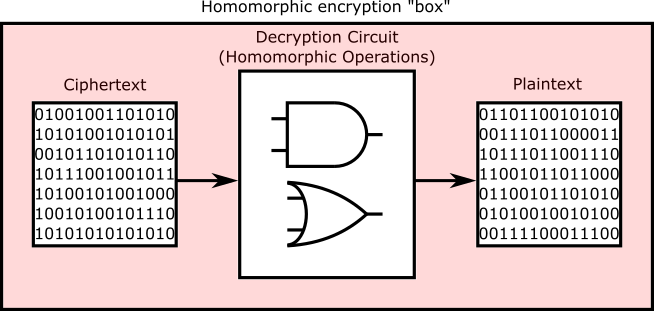
The decryption circuit as executed in an FHE scheme; everything inside the red box remains encrypted, including the output of the decryption circuit. This “box” concept was invented by Craig Gentry to help explain his scheme
This means that we can repeatedly perform operations on the data, stopping every now and again to refresh the ciphertext. As long as we can perform at least one additional NAND operation before we need to perform the decryption circuit, this allows us to execute circuits of any depth without having to decrypt the information.
This process is known as “bootstrapping”, and it’s what made the first FHE scheme (usually denoted as [Gen09]) possible. The original [Gen09] scheme with bootstrapping is sometimes known as “pure” FHE. However, this also has a further big performance hit, as now most of our encrypted operations have to be reserved for performing the decryption circuit!
So under pure-FHE, not only do we have to perform calculations to mimic gates (which is inherently slower than working with unencrypted data), but most of those calculations have to be dedicated to something other than the useful things we want to do with the data.
We’d like it if things were faster. We need better methods and better hardware.
*The other problem on which FHE can be based is the Approximate-Greatest Common Divisor problem, which also uses lattice concepts
There has been much progress in the field of FHE since [Gen09]. Brakerski, Gentry and Vaikuntanathan managed to create a scheme ([BGV12]) in which bootstrapping is optional, using a different and more efficient method of noise management called modulus switching. Both [BGV12] and a different scheme, [CKKS16], are implemented in IBM’s HELib homomorphic encryption library. This library powers IBM’s developer toolkit for FHE, which includes a demonstration of a machine-learning network working on encrypted data.
However, for our purposes we are most interested in a scheme called Toroidal Learning with Errors, or TLWE. This is the scheme used in an open-source FHE library called Concrete, which allows for the rapid development of complex FHE applications including encrypted AI. Concrete was developed by Zama and powers their own offerings in the field of encrypted AI.
[BGV12], [CKKS16] and TLWE can be constructed using a modified version of the learning with errors problem called ring learning with errors (RLWE). We won’t go too deep into the differences between LWE and RLWE in this article, but the main difference is that RLWE is a version of LWE in which the basic addition and multiplication operations are performed over abstract algebraic structures known as rings.
Rings are an extension of the idea of mathematical sets. Sets are one of the more fundamental concepts in mathematics, and formalise the idea of “collections” of things. Some sets are so common that they have individual names and symbols. The integers (the whole numbers over the range -infinity to +infinity) form a set that should be familiar, and this set is usually denoted by the letter Z:
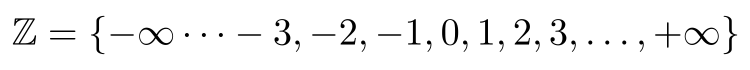
The set of integers
Rings build on this idea by bringing the notions of addition and multiplication into set theory. Rings have a range of formal properties that we won’t fully explore here, but one particularly important property is that adding or multiplying two elements of the ring returns a value which is also an element of the ring.
Think about the integers; adding together two integers always returns another integer, and we can create any other integer in this way. We can say that equipping the set of integers with the abstract idea of addition and multiplication creates a ring.
We can also extend something conceptually similar to the idea of a modulus to ring operations. If you can read and interpret the time shown on a clock, you’re almost certainly familiar with arithmetic in modulus(12), modulus(24), and modulus(60). In brief, it’s the idea that you can define a maximum value beyond which a number larger than the modulus “wraps back around” to the start. This can also be seen as the remainder after the larger number is divided by the number that defines the modulus.
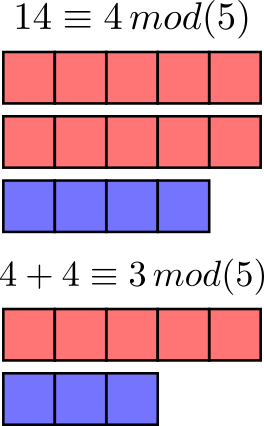
Some basic representations of modular integer arithmetic. The red blocks indicate how many times the modulus value fits completely within the number on the left hand side of the equations above, while the blue blocks indicate the remainder. When it comes to operations in modular arithmetic, the remainder is the important result.
When extended to the formalism of rings, we call the resulting mathematical structure a quotient ring. Because the integers can form a ring, we can use them again for another intuitive example; the basic modular arithmetic in mod(5) that we described above can also be viewed as taking place in the quotient ring:
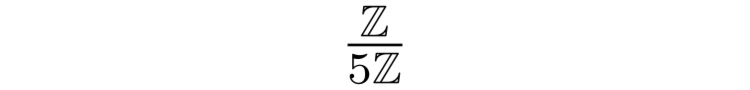
However, rings allow this idea to be extended to more complex mathematical structures too. This is tremendously helpful; in some cases the properties of modular arithmetic form part of the cryptographic basis for a scheme (as is the case for the RSA cryptosystem). More generally, the use of a modulus also allows us to ensure that we’re always working with numbers that a computer can manage efficiently, even when we’re performing operations involving very big numbers.
Ring learning with errors is a version of the learning with errors problem that restricts itself to working in polynomialrings. Polynomials are equations of the form
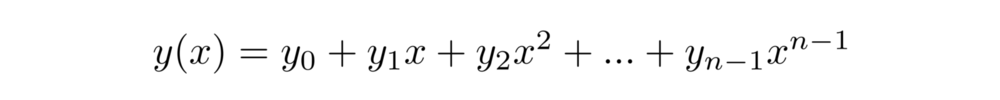
A basic polynomial, where n is the number of terms.
which have their own rules for addition and multiplication. Polynomial systems can also form rings; for example, multiplying the polynomials (3 + x) and (2+x) returns 6 + 5x + x² (which is another polynomial), while adding (3 + x) and (2+x) gives 5 + 2x (also a polynomial). Just as we did for the integers, we can also define a polynomial quotient ring. Particularly common quotient rings in RLWE are
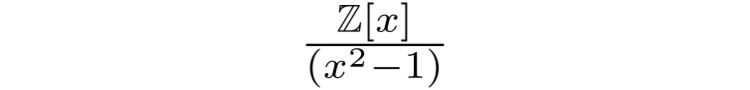
and
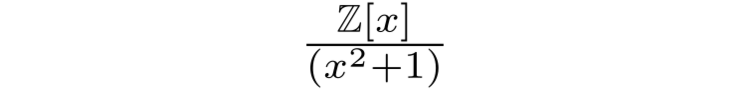
Polynomial multiplication is fairly simple for small polynomials, but can get complicated very quickly. If we’re using the method taught in schools, then the algorithmic complexity in multiplying two polynomials of the same length together is O(n²). However, there’s a more efficient calculation method that uses the Fourier transform; multiplying two polynomials together is equivalent to:
Taking the Fourier transform of each polynomial. In electronic systems, the Fourier transform has algorithmic complexity O(n log(n))
Performing the element-wise multiplication of the two polynomials in Fourier space, an operation with algorithmic complexity O(n)
Performing the inverse Fourier transform (also complexity O(n log(n)) in electronics) on the element-wise product, the output of which gives us the product of the two polynomials.
Polynomial multiplication can therefore be thought of as equivalent to a convolution operation. Conventional electronic systems can perform these steps, but the mathematical construction of FHE means that an astonishing number of polynomial multiplications are required, and even with modern hardware this is the main impediment to timely and efficient FHE operations.
Our optical system was originally designed to perform high speed convolutions with efficiency beyond anything achievable with silicon electronics. While originally conceived of as a means of accelerating Convolutional Neural Networks, we can readily apply it to operations in cryptography too. Here’s our example.
To use our optical hardware for FHE encryption operations, we created our own FHE-supporting code based on a version of the learning with errors problem known as “canonical torus learning with errors” (CTLWE). This is the same method used by Chillotti et al to create the highly efficient TFHE scheme, which is itself based in part on the RLWE variant of the Gentry-Sahai-Waters [GSW13] system.
Our optical system works with 2-dimensional data, so we modified the TLWE method to operate with multinomials, which work like polynomials but with more than one unknown value. For the sake of simplicity, we use the symmetric keyversion of the scheme, in which there’s a single piece of secret information which is used to perform both encryption and decryption.
This is in contrast to the asymmetric key version in which we have two different pieces of information, one of which is used to perform encryption and the other used to perform decryption. The asymmetric key version is more useful because it allows us to create a public-key system for secure communication, but our choice isn’t particularly limiting; the same choice was made by the developers of HElib for the first public version, and by Microsoft for the SEAL library.
Other than these considerations, we’re following the original TFHE encryption method very closely. There’s a great write-up of the scheme by Chillotti, Joye and Pallier here, which (besides providing the background mathematics that describes how and why everything works) also describes a very clever use of the bootstrapping operation to perform tasks useful for artificial intelligence methods.
Central to this utility is the way in which TFHE provides a means of performing a multiplexing operation as part of the bootstrapping. This is more useful than it might sound; not only does this allows the bootstrapping phase to perform useful computation, but it allows non-linear operations (such as the RELU function in a convolutional neural network) to be performed natively, a task which would otherwise require a great many gate-level operations.
This vastly boosts the the speed of FHE-encrypted AI networks, making the Concrete library an excellent starting point for commercial application. Not only that, but the tasks involved in performing this bootstrapping stage are dominated by the need to perform a huge number of Fourier transforms, which is where our hardware can provide a benefit.
For now, we’ll demonstrate how our system can be used to perform the fundamental encryption and decryption operations. Because the maths is quite specialised, in this article we translate the encryption process into pictures.
We begin by generating a key and a set of random multinomial coefficients. In the TLWE case, the key is made of binary values drawn uniformly at random from the binary set {0,1}, while the random coefficients are uniformly random values between 0 and 1. Because we’re working with LWE (and therefore fundamentally working with lattices), it’s also helpful to think of the multinomial coefficients as a multidimensional vector of random values.
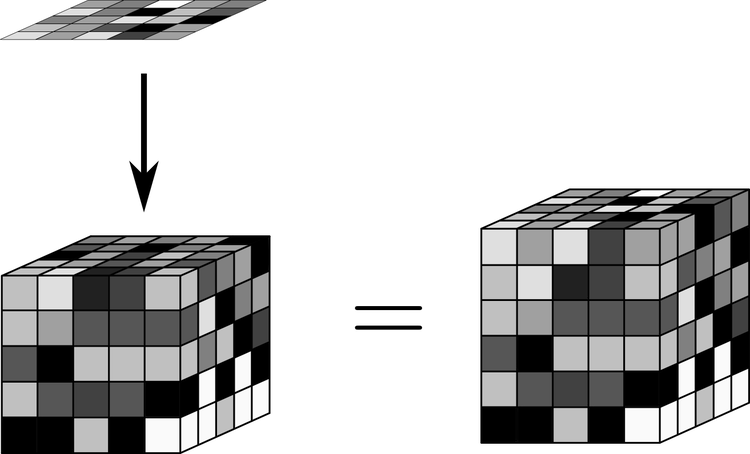
We’re working with our prototype Fourier-optical system (described here), which has a resolution of 5×5 light-emitting elements. To achieve a security parameter of 100 bits, we use 5 5×5 arrays for the key. Both the key and the random vector can therefore be represented as 3-dimensional 5x5x5 arrays as shown below.

The key and some random multinomial coefficients with values between 0 and 1, as shown visually. The random numbers used here are generated using a pseudorandom number generator.
We then want to efficiently multiply the key and the random multinomials together.
Normally, this would be the single most computationally expensive part of the encryption process. However, we can avoidthis computational time and expense by using the optical Fourier transform, a process with O(1) algorithmic complexity!
To do so, we first use our optical system to perform a Fourier transform of each 2-dimensional layer in the key and the block of random multinomials, like so:
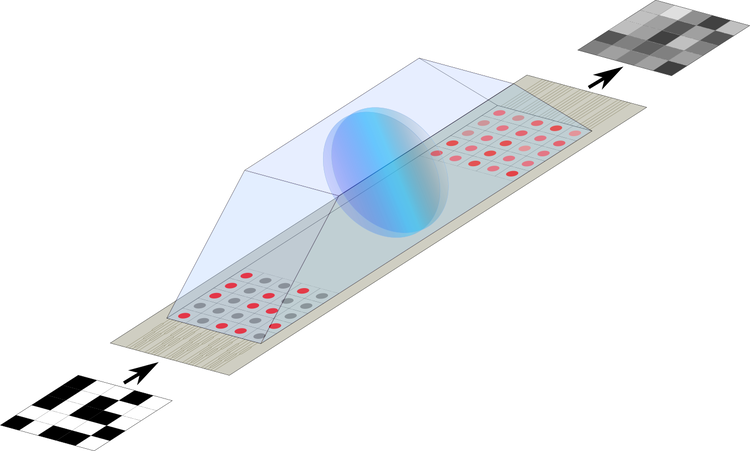
Fourier transforming part of the key using the optical system. We convert each 2D layer of the key into an optical representation, which is then Fourier transformed by the lens and detected on the other side. We’re showing only the real parts of the Fourier transform here, but the output is a complex number.
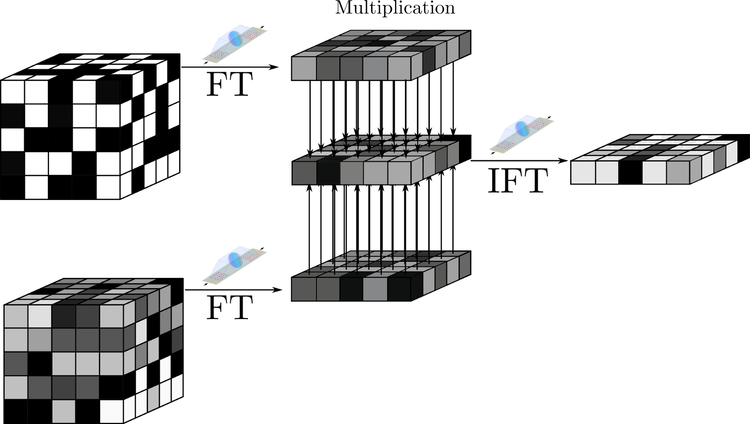
We first perform the element-wise multiplication of the Fourier transform of each layer, and then perform the inverse Fourier transform using the optical system to complete the multiplication. We do this repeatedly to build up the product of the key and the random values. We also retain the original block of random multinomials for later use.
Once we have completed the multiplication process, we then sum the layers of this 3-dimensional product array to create a 2-dimensional array.
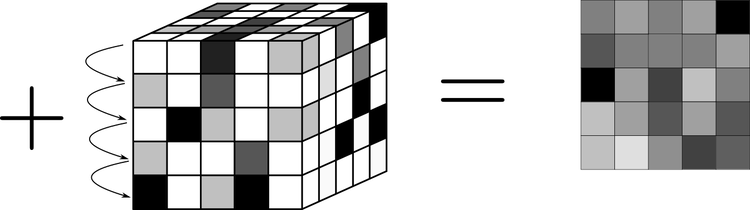
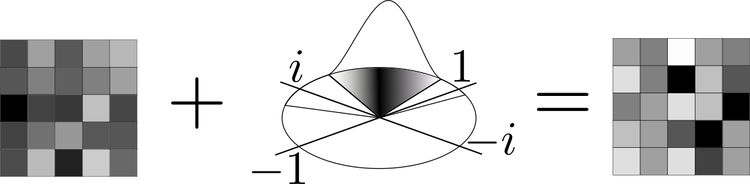
We add this 2-dimensional array to the 2-dimensional message that we want to send. The addition is performed in modulus(1).

We then draw random noise from a Gaussian distribution on the segment [0,1) with periodic boundary conditions (topologically, this is equivalent to drawing from a Gaussian random distribution on the unit circle in the complex plane) and add it to this new 2-dimensional array.
We then append this output array to the original array of random multinomials to create the final ciphertext.
We can now perform homomorphic operations on this ciphertext. Here’s what happened when we encrypted two messages using this technique, homomorphically added them (a simple addition of the respective elements in the two ciphertexts), and then decrypted the result. This is a real result, processed using our optical system.
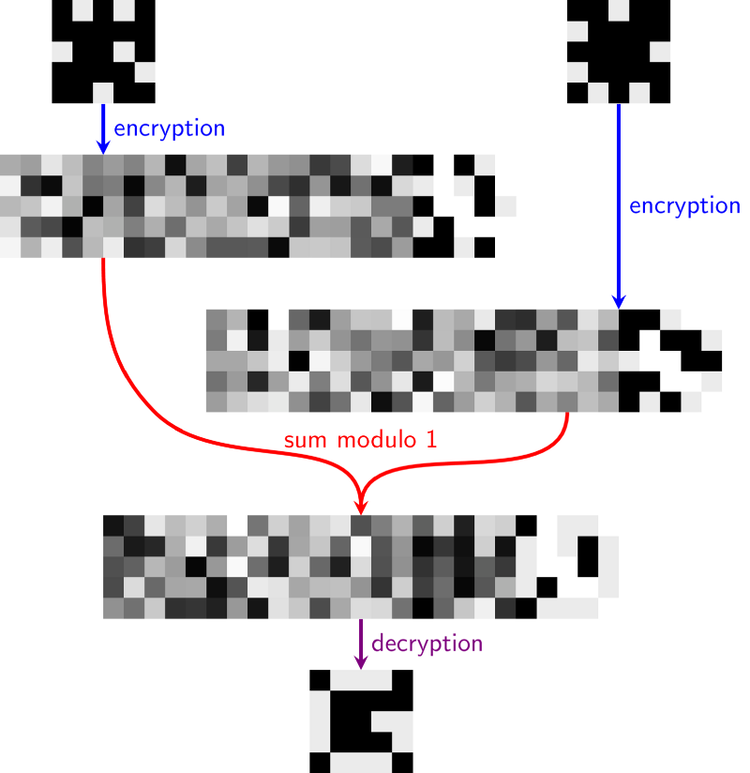
On decrypting the third cipher, we retrieve an output corresponding to what would have happened if we had directly added the two plaintexts together.
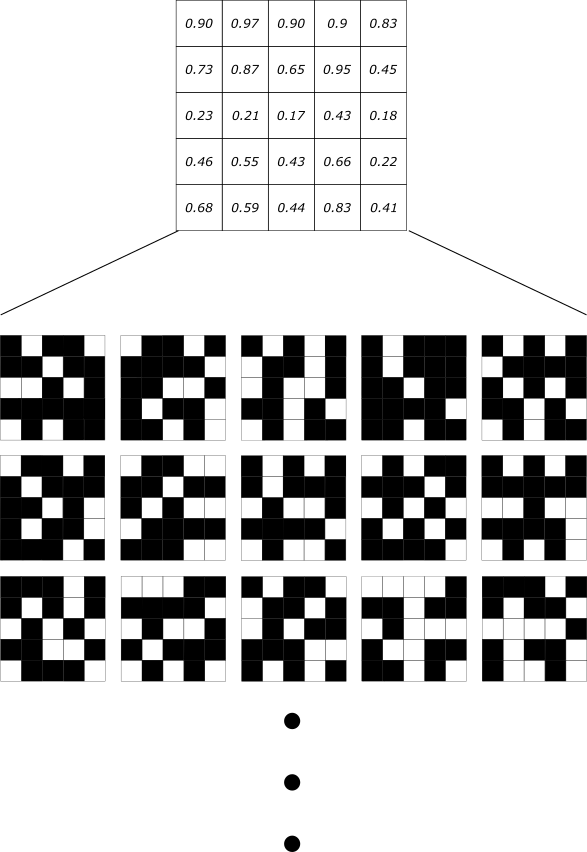
We then extended this process to work on more than 2 ciphertexts. To do so, we needed to generate some data. We created a set of probability distributions over a 5×5 grid like so:
And then used these probabilities to generate 100 random 5×5 messages of binary values with the condition that each element of the message would either be a 1 (with respect to the above probabilities) or a zero
We encrypted these random messages using the above process, homomorphically added the ciphertexts together, and then decrypted the result. The decrypted results obeyed the statistical distribution used to generate the data, indicating that we had successfully performed a homomorphic aggregation. This is a method of collecting data and extracting statistics from it without ever revealing any single unencrypted input (for example the kind of data taken from individual users of a service, who might not want their individual habits revealed), and is becoming increasingly popular as a user security method as more and more data is gathered from a multitude of devices and sensors.
We are currently adapting the larger Concrete library to use Fourier transforms generated using our optical system. Because Fourier-optical computing has demonstrable speed advantages over current electronic methods (both in terms of algorithmic complexity and the physical speed at which an optical system can operate), such a system has major promise as a future hardware accelerator for FHE.
In future articles, we’ll be digging in to the background of post-quantum cryptography to explain why we need it, how it works, and demonstrating an application of our device in performing another post-quantum cryptographic scheme called NTRU. We’re also working on an implementation of the [BGV12] FHE cryptosystem, which we’ll be covering soon.
That’s all for this article. However, for the interested, we present some of the code we used to perform the encryption and decryption process using our optical system in the section below. If you’re interested in learning more about the way our optical computing system works or the problems that we can apply it to, check out the rest of our articles here.
Here, we present the part of our C++ code that invokes our optical system. This is going to be a more technical section than those above, and assumes that you’re familiar with both C++ and some of the fundamental mathematics.
We first show the encryption function. Here, CTLWE is the name of the class and ‘v1D’, ‘v2D’ and ‘v3D’ are aliases for 1, 2 and 3-dimensional arrays (i.e vectors, vectors of vectors, and vectors of vectors of vectors). The integers ‘N1’ and ‘N2’ are the size of the multinomials in each direction (1 plus their degrees in the two variables) and ‘k’ is a parameter of the CTLWE scheme which can be interpreted as the depth of the key. (In the above example, these three parameters are equal to 5.)
v3D<double> CTLWE::encrypt(v2D<double> &message) {
// choose the array a at random
v3D<double> a;
for (int l=0; l<k; l++) {
v2D<double> plane;
for (int i=0; i<N1; i++) {
v1D<double> row;
for (int j=0; j<N2; j++) {
row.push_back(u(gen));
}
plane.push_back(row);
}
a.push_back(plane);
}
// at this stage, a is a 3D array of numbers randomly chosen between 0 and
// 1 with a uniform probability density
// compute b
v2D<double> b = message;
v2D<double> s_dot_a = dot_product(key, a); // this is the bottleneck
add_multinomial(b, s_dot_a);
// at this stage, b is equal to the message plus the dot product of a and the
// key
// add Gaussian noise to b and cast the coefficients of a and b between 0. and 1.
for (int i=0; i<N1; i++) {
for (int j=0; j<N2; j++) {
b[i][j] += d(gen);
b[i][j] = modulo_1(b[i][j]);
for (int l=0; l<k; l++) {
a[l][i][j] = modulo_1(a[l][i][j]);
}
}
}
// append b to a
a.push_back(b);
// return the ciphertext
return a;
}
After the first step, ‘a’ represents a set of random multinomials with coefficients chosen uniformly between 0 and 1 (the variable ‘u’ is the uniform distribution over the interval [0,1) and ‘gen’ is a Mersenne twister PRNG with period 2¹⁹⁹³⁷-1, initialised by the class constructor). The array ‘b’ is first computed as the sum of the message and dot product of the secret key with ‘a’. Some Gaussian noise with zero mean value is then added. The custom function ‘add_multinomial’ adds the second argument to the first, and ‘d’ is a Gaussian distribution with zero mean. The standard deviation of ‘d’ is one of the parameters of the CTLWE class. The custom function ‘modulo_1’ computes the value of a real number to mod(1), returning a value between 0 and 1.
While a quick look at the number of lines may lead us to think that the choice of ‘a’ or casting the coefficient modulo 1 is the main part of the function, the bottleneck is actually the call to the function ‘dot_product’, which performs the dot product of the key and the array of random multinomials. We will come back to it shortly.
Before that, let’s look at the decryption function
v2D<double> CTLWE::decrypt(v3D<double> &cipher) {
// dot product of the cipher and key
v2D<double> s_dot_a = dot_product(key, cipher);
// compute the decrypted message
v2D<double> decrypted = cipher[k];
for (int i=0; i<N1; i++) {
for (int j=0; j<N2; j++) {
// subtract the the coefficient of s_dot_a and round the result
double x = floor(
modulo_1(decrypted[i][j] - s_dot_a[i][j]) * M + 0.5
) / M;
// convert 1 to 0 (they represent the same value in this scheme)
decrypted[i][j] = x < 1 ? x : 0.;
}
}
return decrypted;
}
Here, ‘M’ is the number of different possible values each coefficient can take (it is a parameter of the CTLWE scheme). While the operation of rounding the coefficients takes up several lines of code, it is in practice relatively fast. Converting the values 1 to 0 is fast too. Again, the bottleneck is the dot product function.
With that in mind, let us see how the dot_product function is implemented:
template <typename T, typename U>
v2D<U> CTLWE::dot_product(v3D<T> &a1, v3D<U> &a2) {
// initialize the result with the first product
v2D<U> res = multinomial_multiplication(a1[0],a2[0]);
// add the other products of multinomials
for (int l=1; l<a1.size(); l++) {
v2D<U> plane = multinomial_multiplication(a1[l],a2[l]);
add_multinomial(res, plane);
}
// return the result
return res;
}
It involves two operations on multinomials: addition and multiplication. The first process is much faster than the second one.
The function performing the multinomial multiplication is shown below.
co* mulMult(co* m1, co* m2, int N1, int N2) {
// 1. Dephasing
// initialize the arrays
co* m1_d = (co*) malloc(N1*N2*sizeof(co));
co* m2_d = (co*) malloc(N1*N2*sizeof(co));
// compute each of their coefficients
for (int i=0; i<N1; i++) {
for (int j=0; j<N2; j++) {
// exponent giving the right phase
co exponent = {0., (M_PI*i)/N1 + (M_PI*j)/N2};
co exp_ = co_exp(&exponent);
// multiply the coefficients (i,j) of m1 and m2 by exp_
m1_d[i*N2+j] = co_mul(m1+i*N2+j, &exp_);
m2_d[i*N2+j] = co_mul(m2+i*N2+j, &exp_);
}
}
// 2. Fourier transforms
co* F_m1_d = Fourier2(m1_d, N1, N2);
co* F_m2_d = Fourier2(m2_d, N1, N2);
// 3. Multiplication in Fourier space
// complex array which will store the result
co* F_res_d = (co*) malloc(N1*N2*sizeof(co));
// loop over the coefficients
for (int i=0; i<N1; i++) {
for (int j=0; j<N2; j++) {
// insert the product of the coefficients of the two multinomials
F_res_d[i*N2+j] = co_mul(F_m1_d+i*N2+j, F_m2_d+i*N2+j);
}
}
// 4. Inverse Fourier transform
co* res_d = iFourier2(F_res_d, N1, N2);
// 5. Inverse dephasing
co* res = (co*) malloc(N1*N2*sizeof(co));
for (int i=0; i<N1; i++) {
for (int j=0; j<N2; j++) {
// opposite of the exponent of step 1
co exponent = {0., -(M_PI*i)/N1-(M_PI*j)/N2};
co exp_ = co_exp(&exponent);
// multiply the coefficients i,j of res_d by exp_
res[i*N2+j] = co_mul(res_d+i*N2+j, &exp_);
}
}
// free the temporary pointers
free(res_d);
free(F_res_d);
free(F_m1_d);
free(F_m2_d);
free(m1_d);
free(m2_d);
// return the result
return res;
}
In the full code, the function multinomial_multiplication first calls a wrapper function which turns each of the two arrays into an array of complex numbers. We then call the function mulMult, followed by a function to convert the complex array back into a real one. The conversions have a linear complexity in the number of coefficients, and we omit them here for conciseness. The type “co” is a custom complex type. The functions co_mult and co_exp compute, respectively, the product and exponential of complex numbers. The function mulMult proceeds in 5 steps:
1. add a phase to each coefficient,
2. compute the discrete Fourier transform of each multinomial,
3. perform a component-wise multiplication in Fourier space,
4. compute the inverse Fourier transform,
5. add a phase opposite to that of the first step.
Steps 1, 3, and 5 have a linear complexity. The first and last steps are required to ensure the multiplication is performed in the correct ring of multinomials: without the dephasing, the multiplication in Fourier space would yield a product in the modulus of (X^(N1))–1 and (Y^(N2)–1), where X and Y are the two variables. For the CTLWE algorithm, we want to compute products modulo (X^(N1)+1) and (Y^(N2)+1) instead, which requires a dephasing step. Steps 2 and 4 are the bottlenecks on electronic hardware, with complexity O(n log n) where n is the total number of coefficients (equal to the product of N1 and N2).
The optical computing system under development at Optalysys will be able to significantly accelerate the computation of the Fourier transform and its inverse, thus eliminating the main bottleneck in the encryption and decryption functions. We have already implemented these functions on the current demonstration optical system. While its speed does not reflect what the next device will be able to achieve, we obtained perfect decryption results, including after performing sums of tens of ciphers. This constitutes a proof of principle that the CTLWE scheme (or any cryptosystem relying on polynomial or multinomial multiplication) can be implemented optically, with the potential for significant acceleration and reduction in power usage that optical computing provides.
News
© 2024 All rights reserved Optalysys Ltd
Subscribe
Sign up with your email address to receive news and updates from Optalysys.

