
This article will discuss how Zama’s Concrete library can be leveraged to perform logistic regression on data encrypted via Fully Homomorphic Encryption (FHE).
There are many reasons to be excited by FHE. The ability to perform computations on encrypted data is a game changer for many fields. Using FHE, users can have encrypted data processed by third parties. Processing is carried out entirely on encrypted data, yielding encrypted results.
Thus, a user can have their data processed by, say, a proprietary AI model owned by a medical company, without needing to share their data or compromise their privacy. In the event that the medial company experienced a data breach, no user information would be retrievable. It would all be encrypted.
Although this technology already exists, FHE requires a lot of compute power and can be prohibitively slow, limiting real work use cases. However, at Optalysys, we are currently building optical compute hardware that can accelerate real-world FHE workloads by over two orders of magnitude. We thus see our optical technology as the key to unlocking the huge potential of FHE.
We’ve already covered how we can merge Zama’s Concrete and Concrete-Boolean libraries with our technology, and used this combined system to carry out a range of tasks in encrypted space. We’ve also been transitioning from applications which are interesting (performing Conway’s Game of Life in encrypted space) through to applications which are useful.
Practical FHE
It’s well established that FHE is going to be revolutionary for the way that data can be handled, managed and analysed, which in turn is going to open up a vast new market in providing encrypted data services. However, to fully realise the commercial value, FHE has to be accessible to a far broader developer base than it currently is.
So to tie FHE together with familiar software development tasks, in this article we’ll be taking things to another level. We’ll demonstrate how we can securely implement a powerful data analysis tool and apply it to the test case of evaluating encrypted medical data. We’ll be leveraging the power of Zama’s Concrete library. This library has made it easier than ever to start applying powerful FHE techniques.
We consider the situation where a medical company has created a logistic regression AI model to predict the whether a patient has a disease based on their medical record. The patient would like to know if they have a disease, but do not want to expose their data to any security risks incurred by transmitting their data. We will therefore use FHE to allow the model to work with encrypted data.
The two diagrams below explain why FHE is necessary for such a system to be secure:

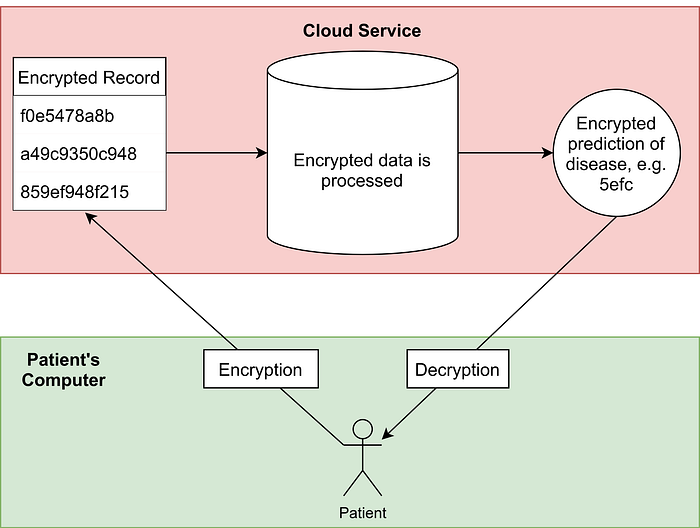
Leveraging FHE will allow this to take place; the user will receive a prediction of whether they have a disease, without their medical record being exposed to the third party, or any adversaries on the way.
Before discussing the FHE implementation, we will first introduce logistic regression and build a basic model.
Logistic regression is a supervised learning technique to classify data. A logistic regression model is trained by optimising coefficients that are applied to a feature vector as a linear combination. Probabilistic predictions can be obtained by passing the output of the linear combination through a logistic function.
More formally, a scalar prediction y in the range (0, 1) is obtained by applying a logistic function (e.g. sigmoid) to a scalar value v, which is the output of dot product between a feature vector X and a learned weight vector W.
The prediction y can be interpreted as the probability of the input vector corresponding to one of two classes. A bias or intercept term can be added explicitly, or encoded via an additional weight and concatenating a 1 onto the feature vector.

Logistic regression is essentially linear regression, but instead of predicting a continuous output variable, it predicts a binary classification probability by applying a logistic function to the output.
Thus if we threshold the model output at 0.5, we can use it directly as a binary classifier. In this article, we are not interested in the output probability, only the class. As such we can omit the sigmoid function, instead thresholding the output of the linear model at 0.
By plotting the data, we can visualise the decision boundary of the model. As we have a 9-dimensional feature vector, its hard to visualise, so we will plot the data in 2 dimensions, taking only the two features with the largest absolute coefficients in our model and plotting these on the x and y axes.
Points on the plot represent individual data samples, with their associated class label represented using colour. Below is a plot showing the output of our model’s predictions vs. the ground truth for our dataset. Positive predictions are shown in orange, negative blue.
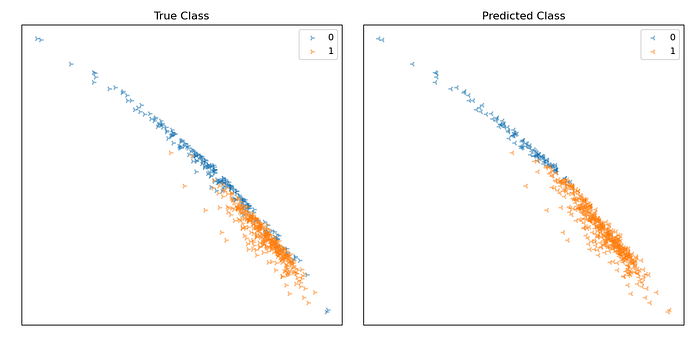
From the plots, we can see that many samples are being classified correctly. There seems to be a linear decision boundary that cuts the data fairly well, though some are being classified incorrectly.
After a bit of post processing of the data in Python to retrieve the class predictions, we can plot the predictions of the model. We will plot them in the same way as before: taking the two dimensions of the input features with the highest associated coefficients in the model. We will compare the output predictions of the plaintext model with the model that works on encrypted inputs.
Encrypted model using FHE:

Plaintext model:
The two plots look identical. This is good news as it suggests that the model that uses encrypted data seems to be working as well as the original plaintext model.
However, to confirm this, we ran the binary_prediction_similarity function described earlier to compare the two models’ predictions. We found a prediction similarity of 0.995 or 99.5%. This is a result of the models disagreeing on 3 single data points out of 569, which may be as a result of precision limitations in the chosen parameters for Concrete.
This means that the model converted to run on encrypted inputs works almost identically to its plaintext counterpart. We were happy with the balance of runtime and accuracy, although it is possible to achieve even greater accuracy.
If, for instance, we used a higher bit precision in our encoder, perhaps with a larger polynomial size, it is likely that we could remove any discrepancy between the two models, but there would be an associated runtime cost.

