
Optalysys have produced a proof-of-concept prototype system incorporating the above technologies and considerations. This system has a GC resolution of 5 × 5 and the refractive index of the individual MZIs is modulated by thermal means. This limits the practical speed of the system as the use of these modulators introduces thermal cross talk, and heater values must be changed comparatively slowly (on the order of microseconds).

Figure 8: The silicon-photonic prototype, the precursor to a fully bonded unit, as mounted in the demonstrator system. The fibre-optic input for the laser and the coupling optics can be seen on the right. The edge of the prism unit is positioned directly over the emitting GC array.
The prototype system is mounted on a custom-manufactured board of drive electronics that manages received data from a host computer, which is encoded into the system via control of the thermal modulators. 1550 nm C-band laser light is provided by a GoLight tunable light source coupled into a branching tree multiplexer by a fibre-optic connection. The free-space stage of the optics is a combined prism-lens unit which is mounted directly above the grating coupler array. The mounting of the system to the drive electronics, the fibre-optic coupling
and the edge of the prism in position above the emissive grating coupler array can be seen in Figure 8. To facilitate the current calibrations being performed on the device, no MLA is present at either the emissive or receiving plane, thus higher order light is transmitted alongside the dominant Fourier plane elements. The effects of this additional light are visible in the results presented in the following Section.
The following results show the input pattern to the device, the anticipated intensity readout as calculated digitally, and the directly observed output plane. These results are provisional for a device currently undergoing calibration and characterisation. To make the calibration easier, we restricted ourselves to three possible values for each input pixel: −1, 0, or +1. We are currently in the process of performing a finer calibration which will allow for a broad range of real and complex values. Pixel positions are indicated by the label on the axes.
For Figures 9-13, we provide a root mean squared (RMS) error as calculated through the following method. We first normalize the output image so that its values lie between 0 and 1. We then compute the square of the difference with the squared absolute value of the Fourier transform of the input image, average the result over the 25 pixels, and take the square root. This result provides an estimate of the error on each pixel. As can be seen below, this error is smaller than 0.20, and smaller than 0.15 for most of the figures. We expect that a more precise calibration will bring the errors down to less than 0.1 and allow the output to be measured with at least 2 bits of accuracy.

Figure 9: A black (inverse) diagonal. Input values are −1 (black), 0 (grey), and 1 (white). The total RMS error is 0.14.
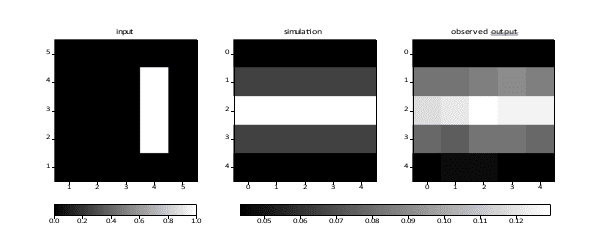
Figure 10: A small offset bar. Input values are 0 (black) and 1 (white). The total RMS error is 0.12.
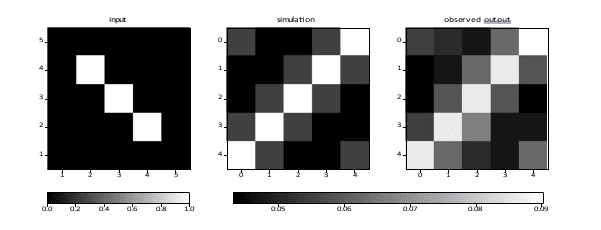
Figure 11: A diagonal pattern. Input values are 0 (black) and 1 (white). The total RMS error is 0.17.
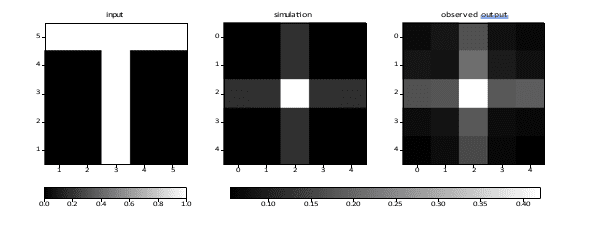
Figure 12: A T-shape. Input values are 0 (black) and 1 (white). The total RMS error is 0.13.
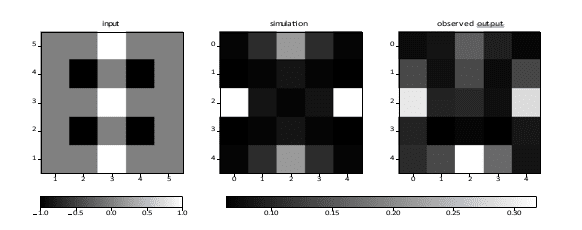
Figure 13: A set of vertical and horizontal line patterns. Input values are −1 (black), 0 (gray), and 1 (white). The total RMS error is 0.14.
The optical device can also be used to compute the full complex Fourier transform of an input by comparing the measured intensities of the output with that of a reference. In the future, this comparison will be performed using balanced photodiodes, allowing to measure both the amplitude and phase in one frame. As a preliminary step, we developed a method to compute the complex Fourier transform from images of the output plane for different outputs.
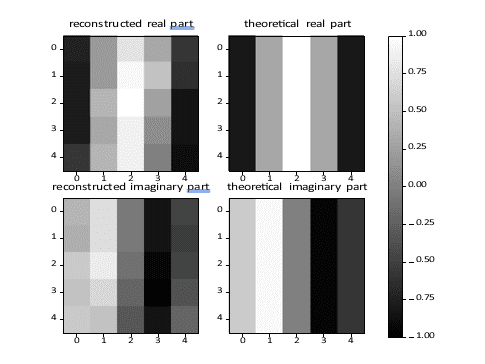
Figure 14: Fourier transform for an input with one bright pixel at position (2,1).
Figures 14 and 15 show results for the Fourier transform for two inputs having
one pixel in its “on” state each. In each figure, the left panels show the real and imaginary parts of the Fourier transform as obtained using the optical device, and the right panels show the exact discrete Fourier transform of the input. A precise estimate on the complex Fourier transform will require a more precise calibration, which is in progress. However, as illustrated on these two images, preliminary results indicate good accuracy. (At the moment, the RMS error is close to 20%.)
As for the squared absolute value, we expect to reach at least two bits of accuracy.
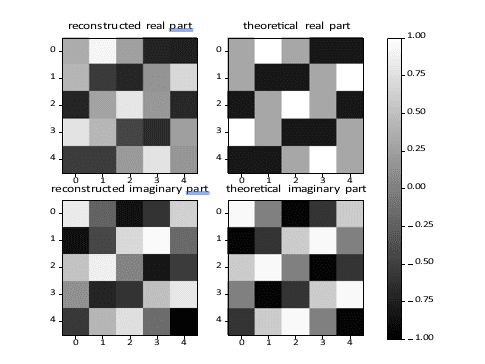
Figure 15: Fourier transform for an input with one bright pixel at position (2,3).
By far the most significant increase in system operating speeds is offered by adopting an alternative modulation method to the thermal modulators currently used on the demonstrator device. SiP MZIs are also available in the form of the PN-junction MZI, which manipulates the charge carrier density in doped silicon via broadening of the junction depletion layer to dynamically alter the refractive index. Such MZI arrays can be driven at very high speed (up to 50 Gbits/s per MZI) with 4-level Pulse Amplitude Modulation (PAM4).
The extreme operating speed and throughput of an optical system requires additional consideration as to the manner in which it is integrated into an electronic host. An example is an optical device operating at 9 × 9 resolution at 10 GHz with a detection depth of 2 bits, which has a maximum throughput for FT calculation of 1.62 TBits/s. Higher operating speeds, resolutions and bit-depth are entirely plausible with current technology. Depending on these factors and the device-level integration of the optical system, this throughput may exceed the rate at which data may be transferred over conventional electronic interconnect standards. If used as a desktop co-processor through the same Peripheral Component Interconnect Express (PCI-e) framework as a Graphics Processor Unit (GPU), such a device would effectively reach the Von Neumann bottleneck even for next-generation data transfer standards such as PCI-e v6.0, which supports 128 GB/s (1.024 TBits/s) per direction with a 16-lane configuration. As a component in a stand-alone unit such as a PC motherboard or server rack, achieving peak performance for an MFT unit will likely require the development of a dedicated high-throughput connection positioned near to key processing units and memory.
To take full advantage of the high-speed operation capabilities of the MFT unit in the near future, we therefore suggest integration into existing optical applications. The native use of 1550 nm light in both the MFT unit and the high-bandwidth optical transceivers currently used in data-centres makes the embedding of the MFT unit in these inherently optical systems a natural proposition. The versatility of the Fourier transform and the very high data throughput the device can manage provides significant scope for the transformation of data in-flight. This would allow a range of applications to work at speeds that vastly exceed their current digital implementation. In this use-model, we envisage a world in which data transmitted to the cloud for processing in a neural network arrives on the server having already been converted into a more efficient representation in the Fourier domain as it passes through the network connection, without incurring the time and energy intensive use of the digital Fast Fourier Transform. Alternatively, as the need for quantum-secure communications in the near future becomes more pressing, an MFT unit embedded into an optical transceiver could support the rapid execution of operations that support next-generation lattice-based cryptography. We provide more detail on this application in the following Section.

